 分词&模糊匹配
分词&模糊匹配
# 分词匹配相关功能API
match(boolean condition, R column, Object val);
matchPhase(boolean condition, R column, Object val, Float boost);
matchAllQuery();
matchPhrasePrefixQuery(boolean condition, R column, Object val, int maxExpansions, Float boost);
multiMatchQuery(boolean condition, Object val, Operator operator, int minimumShouldMatch, Float boost, R... columns);
queryStringQuery(boolean condition, String queryString, Float boost);
prefixQuery(boolean condition, R column, String prefix, Float boost);
1
2
3
4
5
6
7
2
3
4
5
6
7
注意
注意:涉及需要分词匹配的字段索引类型必须为text或keyword_text(不指定时默认为此类型),并为其指定分词器,所需分词器需提前安装,否则将使用es默认分词器,对中文支持不好.
# 模糊匹配相关功能API
// 注意 like底层对应es的wildcard查询,传入的值会被默认拼接上*号通配符 例如 *老汉*
like(boolean condition, String column, Object val, Float boost);
// likeLeft会在值左侧拼接通配符* 例如 *老汉
likeLeft(boolean condition, String column, Object val, Float boost);
// likeRight会在值右侧拼接通配符* 例如老汉*
likeRight(boolean condition, String column, Object val, Float boost);
1
2
3
4
5
6
2
3
4
5
6
# 查询API及字段索引类型参考
关于如何选择使用上述API以及如何正确建立对应索引,不了解ES的同学可以参考下表:
| ES原生 | Easy-Es | keyword类型 | text类型 | 是否支持分词 |
|---|---|---|---|---|
| term | eq | 完全匹配 | 查询条件必须都是text分词中的,且不能多余,多个分词时必须连续,顺序不能颠倒 | 否 |
| wildcard | like/likeLeft/likeRight | 根据api模糊匹配 like全模糊,likeLeft左模糊,likeRight右模糊 | 不支持 | 否 |
| match | match | 完全匹配 | match分词结果和text的分词结果有相同的即可,不考虑顺序 | 是 |
| matchPhrase | matchPhrase | 完全匹配 | matchPhrase的分词结果必须在text字段分词中都包含且顺序必须都相同,而且必须都是连续的. | 是 |
| matchPhrasePrefixQuery | matchPhrasePrefixQuery | 不支持 | matchPhrasePrefix与matchPhrase相同,除了它允许在文本的最后一个词上的前缀匹配. | 是 |
| multiMatchQuery | multiMatchQuery | 完全匹配 | 全字段分词匹配,可实现全文检索功能 | 是 |
| queryStringQuery | queryStringQuery | 完全匹配 | queryString中的分词结果至少有一个在text字段的分词结果中,不考虑顺序 | 是 |
| prefixQuery | prefixQuery | 完全匹配 | 只要分词后的词条中有词条满足前缀条件即可 | 是 |
- 分词匹配
- 例: match("content", "老王")--->content 包含关键词 '老王' 如果分词粒度设置的比较细,老王可能会被拆分成"老"和"王",只要content中包含"老"或"王",均可以被搜出来,其它api可参考下面代码示例.
# 代码示例
@Test
public void testMatch(){
// 会对输入做分词,只要所有分词中有一个词在内容中有匹配就会查询出该数据,无视分词顺序
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.match(Document::getContent,"技术");
List<Document> documents = documentMapper.selectList(wrapper);
System.out.println(documents.size());
}
@Test
public void testMatchPhrase() {
// 会对输入做分词,但是需要结果中也包含所有的分词,而且顺序要求一样,否则就无法查询出结果
// 例如es中数据是 技术过硬,如果搜索关键词为过硬技术就无法查询出结果
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.matchPhrase(Document::getContent, "技术");
List<Document> documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
@Test
public void testMatchAllQuery() {
// 查询所有数据,类似mysql select all.
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.matchAllQuery();
List<Document> documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
@Test
public void testMatchPhrasePrefixQuery() {
// 前缀匹配查询 查询字符串的最后一个词才能当作前缀使用
// 前缀 可能会匹配成千上万的词,这不仅会消耗很多系统资源,而且结果的用处也不大,所以可以提供入参maxExpansions,若不写则默认为50
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.matchPhrasePrefixQuery(Document::getCustomField, "乌拉巴拉", 10);
List<Document> documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
@Test
public void testMultiMatchQuery() {
// 从多个指定字段中查询包含老王的数据
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.multiMatchQuery("老王", Document::getTitle, Document::getContent, Document::getCreator, Document::getCustomField);
// 其中,默认的Operator为OR,默认的minShouldMatch为60% 这两个参数都可以按需调整,我们api是支持的 例如:
// 其中AND意味着所有搜索的Token都必须被匹配,OR表示只要有一个Token匹配即可. minShouldMatch 80 表示只查询匹配度大于80%的数据
// wrapper.multiMatchQuery("老王",Operator.AND,80,Document::getCustomField,Document::getContent);
List<Document> documents = documentMapper.selectList(wrapper);
System.out.println(documents.size());
System.out.println(documents);
}
@Test
public void queryStringQuery() {
// 从所有字段中查询包含关键词老汉的数据
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.queryStringQuery("老汉");
List<Document> documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
@Test
public void prefixQuery() {
// 查询创建者以"隔壁"打头的所有数据 比如隔壁老王 隔壁老汉 都能被查出来
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.prefixQuery(Document::getCreator, "隔壁");
List<Document> documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
@Test
public void like() {
// 等价于MySQL中 like %汉推% 像老汉推...就可以被查出来
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.like(Document::getTitle, "汉推");
List<Document> documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
@Test
public void likeLeft() {
// 等价于MySQL中 like %汉 像老汉就可以被查出来
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.likeLeft(Document::getTitle, "汉");
List<Document> documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
@Test
public void likeRight() {
// 等价于MySQL中 like 老% 像老汉就可以被查出来
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.likeRight(Document::getTitle, "老");
List<Document> documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
# queryString 妙用
由于queryString可以检索keyword和text两种类型,所以有一部分使用场景是如下图这样的,所有查询字段,查询类型,匹配规则等都是不固定的,由用户自由来选,这种情况下,您除了可以使用我们提供的四大嵌套查询中的or()来实现,还可以通过queryStringQuery API来解决.
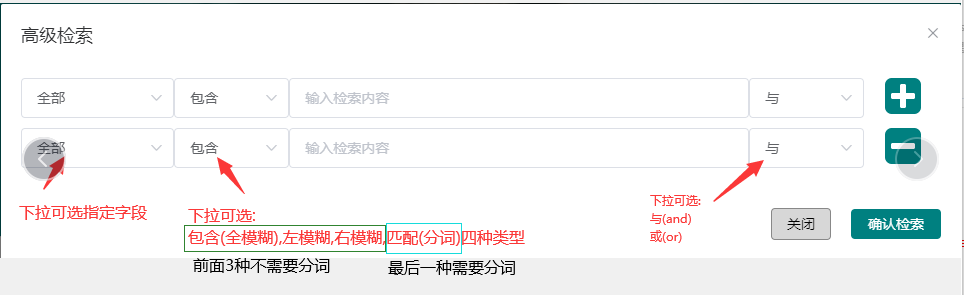
我们可以用StringBuilder把查询字段和值拼接进去,组装成最终的查询语句. 以上图为例,我演示一个场景,请忽略场景合理性,因为是我瞎xx选的:假设我的查询条件是:字段:创建者 等于老王,且创建者分词匹配"隔壁"(比如:隔壁老汉,隔壁老王),或者创建者包含大猪蹄子,对应的代码如下:
@Test
public void testQueryString() {
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
StringBuilder sb = new StringBuilder();
sb.append("(")
.append("(")
.append("creator.keyword")
.append(":")
.append("老王")
.append(")")
.append("AND")
.append("(")
.append("creator")
.append(":")
.append("隔壁")
.append(")")
.append(")")
.append("OR")
.append("(")
.append("creator.keyword")
.append(":")
.append("*大猪蹄子*")
.append(")");
// sb最终拼接为:((creator.keyword:老王)AND(creator:隔壁))OR(creator.keyword:*大猪蹄子*) ,可以说和MySQL语法非常相似了
wrapper.queryStringQuery(sb.toString());
List<Document> documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
前端参数页面每传递一行查询参数,我们往sb中append对应参数就完事了,是不是很简单,没错,但是代码不优雅,可咋整? 老汉已经给你们想好出路了,我们提供了工具类,其全路径为:cn.easyes.core.toolkit.QueryUtils 我们用使用该工具类重构上面的代码,如下:
@Test
public void testQueryStringQueryMulti() {
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
String queryStr = QueryUtils.combine(Link.OR,
QueryUtils.buildQueryString(Document::getCreator, "老王", Query.EQ, Link.AND),
QueryUtils.buildQueryString(Document::getCreator, "隔壁", Query.MATCH))
+ QueryUtils.buildQueryString(Document::getCreator, "*大猪蹄子*", Query.EQ);
wrapper.queryStringQuery(queryStr);
List<Document> documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
是不是优雅了很多,其中的枚举Query和Link我也已经为你们封装好了,直接使用即可,不懂其枚举含义也可以直接点开查看,我在源码中有详细注释.
帮助我们改善此文档 (opens new window)
上次更新: 2024/07/16