 避坑指南
避坑指南
提示
古语有云"工欲善其事,必先利器","磨刀不误砍柴工"...
ES本身功能庞大且复杂,对开发者有极高的要求,通常高级开发者才能驾驭,但Easy-Es的使用者不乏一些ES小白或是刚入门的JAVA初学者, 为了让这部分尽量避免踩坑, 节省更多时间,特此总结一篇避坑指南,在正式使用EE之前,不妨花三五分钟学习一下,可以帮各位在使用中避免踩坑,从而节省大量时间.
遇到问题尽量先从使用角度是否规范,版本是否兼容去下手,我们已提供的API都是有测试用例覆盖,单测覆盖率高达95%+,并有社区大量用户以及生产环境实测佐证无缺陷的,不要做 键盘侠,喷子,上来就觉得框架遍地都是Bug,各种喷,实际上是自己菜的抠脚...要么不看文档瞎j*用,要么是ES基础太差踩了ES的坑.这类用户其实对自己技术成长一点帮助都没有, 正确姿势应该是按文档规范使用,并且遇到问题先debug,看看源码,问问度娘等多方途径,确实解决不了,可以加入我们答疑群,我们会协助解决,确认为缺陷的话,Block级别缺陷我 们会在24H内修复,其它等级缺陷,会立即给出解决和规避方案,并尽快发版修复.
# ES版本及SpringBoot版本
由于我们底层用了ES官方的RestHighLevelClient,所以对ES版本有要求,要求ES和RestHighLevelClient JAR依赖版本必须为7.14.0(EE2.1.0版本后升级为7.17.8,对es的兼容为7.x及8.x),至于es客户端,实际 测下来7.X任意版本都可以很好的兼容.
值得注意的是,由于SpringData-ElasticSearch的存在,Springboot它内置了和ES及RestHighLevelClient依赖版本,这导致了不同版本的Springboot实际引入的ES及RestHighLevelClient 版本不同,而ES官方的这两个依赖在不同版本间的兼容性非常差,进一步导致很多用户无法正常使用Easy-Es,抱怨我们框架有缺陷,实际上这只是一个依赖冲突的问题. 我们在项目启动时做了依赖校验,如果您的项目在启动时可以在控制台看到打印出级别为Error且内容为"Easy-Es supported elasticsearch and restHighLevelClient jar version is:7.14.0 (EE2.1.0版本后为7.17.8),Please resolve the dependency conflict!" 的日志时,则说明有依赖冲突待您解决. 解决方案其实很简单,可以像下面一样配置maven的exclude移除Springboot或Easy-Es已经声明的ES及RestHighLevelClient依赖,然后重新引入,引入时指定版本号为7.14.0(EE2.1.0版本后升级为7.17.8)即可解决.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</exclusion>
<exclusion>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
</exclusion>
<exclusion>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.17.8</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.17.8</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.17.8</version>
</dependency>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
如果你是个菜的抠脚的懒汉,也可以简单粗暴的把springboot版本调整到2.5.5,其它都不需要调整,也可以勉强正常使用.
另外您在使用过程中如果碰到问题,不妨先从问答中寻找答案,如果未找到您期望的答案,您还可以下载我们源码,从test模块下找到all包,该包中的测试类包含了easy-es几乎全部核心功能,可以供您参考. 如果仍未解决,您可以通过我们官网上方的加入社区讨论加入我们的答疑群,我们会安排专人帮您无偿解答,但尽量不要问一些十万个为什么,大家时间都很宝贵,我们资源也非常有限!
# ES索引的keyword类型和text类型以及termQuery,match,match_phrase区别

对ES索引类型以及以上查询API已经了解的可直接跳过此段介绍.
ES中的keyword类型,和MySQL中的字段基本上差不多,当我们需要对查询字段进行精确匹配,左模糊,右模糊,全模糊,排序聚合等操作时,需要该字段的索引类型为keyword类型,否则你会发现查询没有查出想要的结果,甚至报错. 比如EE中常用的API eq(),like(),distinct()等都需要字段类型为keyword类型.
当我们需要对字段进行分词查询时,需要该字段的类型为text类型,并且指定分词器(不指定就用ES默认分词器,效果通常不理想). 比如EE中常用的API match()等都需要字段类型为text类型. 当使用match查询时未查询到预期结果时,可以先检查索引类型,然后再检查分词器,因为如果一个词没被分词器分出来,那结果也是查询不出来的.
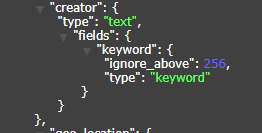
当同一个字段,我们既需要把它当keyword类型使用,又需要把它当text类型使用时,此时我们的索引类型为keyword_text类型,EE中不指定字段类型时,则默认该字段类型为此keyword+text双类型,双类型如下图所示,值得注意的是,当我们把该字段当做keyword类型查询时,ES要求传入的字段名称为"字段名.keyword",当把该字段当text类型查询时,直接使用原字段名即可. 值得庆幸的是,自2.0版本起,框架内部对此作了处理,默认会根据当前字段的索引类型和查询的类型来决定实际到底使用哪种类型,.keyword后缀框架会自动拼接,进一步减少了小白踩此坑的可能,如果您不希望框架自动根据上下文拼接.keyword后缀,您也可以通过配置文件关闭此项智能化功能, easy-es.global-config.db-config.smartAddKeywordSuffix=false
# 字段id
由于框架很多功能都是借助id实现的,比如selectById,update,deleteById...,而且ES中也必须有一列作为数据id,因此我们强制要求用户封装的实体类中包含字段id列,否则框架不少功能无法正常使用.
public class Document {
/**
* 推荐方式1: es中的唯一id,不加任何注解或@IndexId(type=IdType.NONE) 此时id值将由es自动生成
*/
private String id;
/**
* 不推荐方式2:如果你想自定义es中的id为你提供的id,比如MySQL中的id,请将注解中的type指定为customize或直接在全局配置文件中指定,此时你便可以在插入数据时赋值给id
*/
@IndexId(type = IdType.CUSTOMIZE)
private Long id;
/**
* 推荐方式3:如果你确实有需求用到其它数据库中的id,不妨在加了推荐方式1中的id后,再加一个字段类型为keyword的列,用来存储其它数据库中的id
*/
@IndexField(fieldType = FieldType.KEYWORD)
private Long mysqlId;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
强烈建议采用推荐方式,直接在实体类加一行 private String id 即可,不要画蛇添足,如果你真期望在es中检索mysql库中对应数据的id,不妨另起一列,按推荐方式3写. 因为如果你强行用mysql或其它算法生成的id作为es的_id,此时插入数据时es会在所有分片上计算该id是否具备唯一性,这个过程随着数据量的大小,会对服务有致命影响, 并且强烈推荐不要使用es的_id进行排序,这也会容易导致OOM,原因类似,es官方也不推荐你这么做,但你可以像推荐方式3一样新加一行keyword类型索引字段,比如叫mysqlId, 通过该新增的字段进行CRUD及排序等各种操作,此时性能就不会受影响了,总之记住,id就用es自己生成的,不建议自己玩花活.
在调用insert方法时,如果该id数据在es中不存在,则新增该数据,如果已有该id数据,则即便你调用的是insert方法,实际上的效果也是更新该id对应的数据,这点需要区别于MP和MySQL.
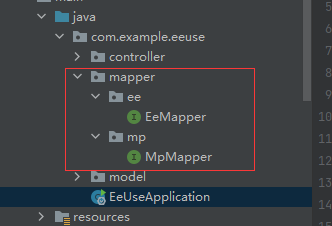
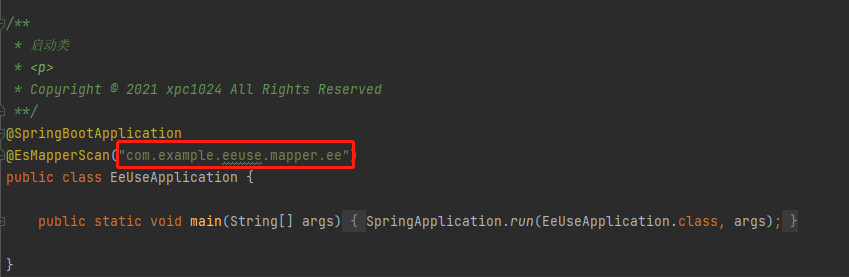
# 项目中同时使用Mybatis-Plus和Easy-Es
在此场景下,您需要将MP的mapper和EE的mapper分别放在不同的目录下,并在配置扫描路径时各自配各自的扫描路径,如此便可共存使用了,否则两者在SpringBoot启动时都去扫描同一路径,并尝试注册为自己的bean,由于底层实现依赖的类完全不一样,所以会导致其中之一注册失败,整个项目无法正常启动.可参考下图:
祝各位主公使用愉快,使用过程中有任何疑问及建议,可添加我微信252645816反馈,我们也有专门的答疑群为各位主公们提供免费服务.